Добрый день! Последняя версия Балаболки временами у меня на виндовс 11 не запускается. В Менеджере задач процесс Балаболки появляется, но нет интерфейса. Если убить процесс и снова попытаться запустить, результат остается прежним: процесс есть, а программы нет. Помогает перезагрузка компьютера. Проблема у меня?
faorekh Не знаю, в чем может быть проблема. Другие пользователи тоже сообщали о том, что такое иногда происходит на Windows 10/11: за несколько лет ничего выяснить не удалось, причина неизвестна. Если кто-нибудь в курсе, почему такое случается, напишите, пожалуйста.
Мне задают вопрос, почему в "Балаболке" перестал работать доступ к онлайн-демо голосов Google. Ответ очевидный: сайт демо начал использовать технологию TLS ECH (Encrypted Client Hello), а сайты с такой технологией сейчас заблокированы в России.
Здраствуйте! Не уверен туда ли пишу, может надо отдельную тему создавать? Но пока отпишу здесь.
Собственно, решил сегодня обновить мой любимый DocVoicer и столкнулся со следующей проблемой: программа перестала перекрашивать некоторые прочитанные знаки препинания.
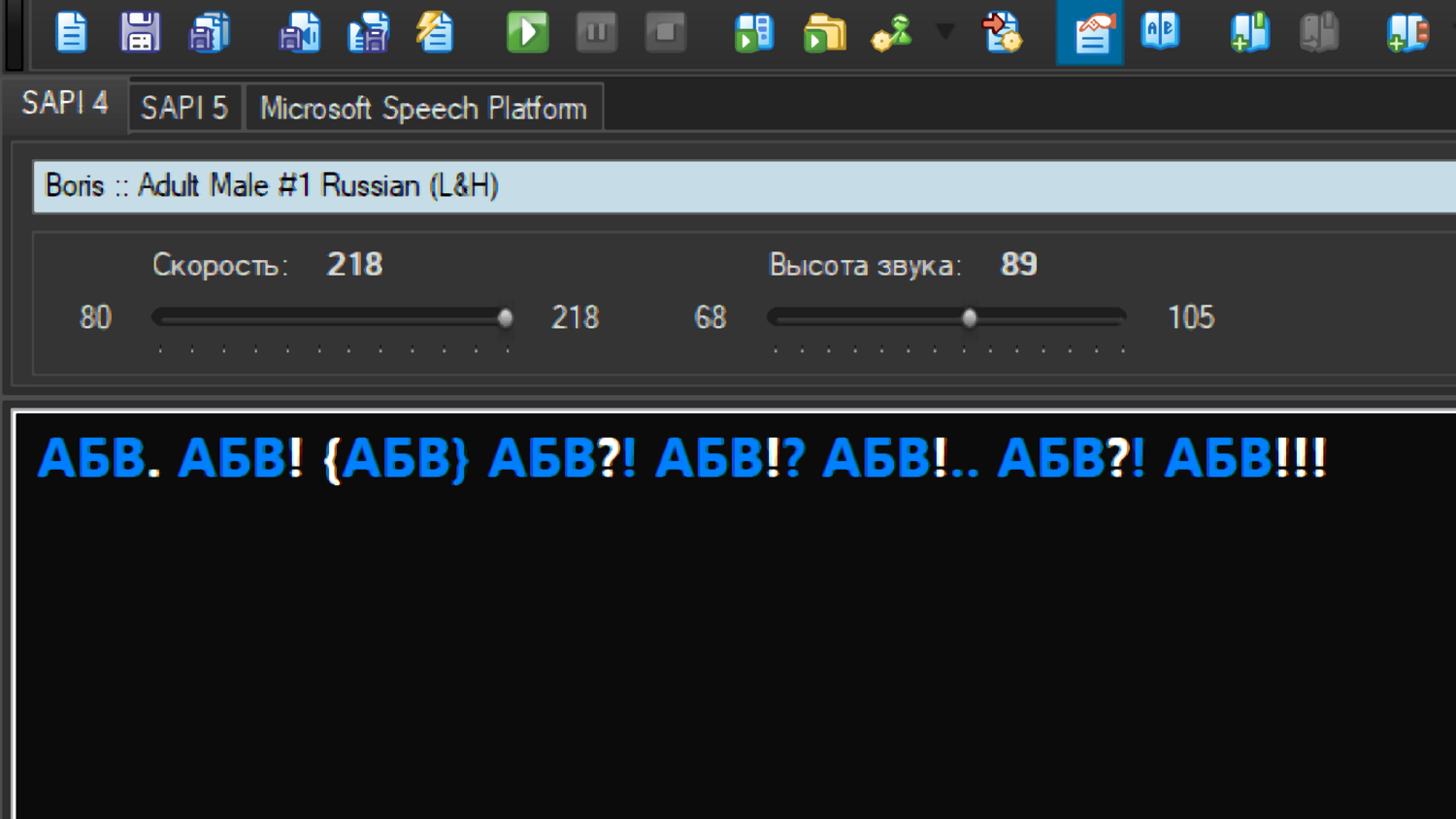
Сразу хочу отметить что проблема возникает в SAPI 4 голосах L&H tts 3000 Russian. По крайней мере в SAPI 5 от Microsoft такой проблемы не наблюдается, а других у меня не установлено.
Я понимаю что эти голоса - пережиток викторианской эпохи. Собственно, насколько я помню, на старом форуме я даже спрашивал у Вас почему эти голоса пропадают после повторного запуска программы, оказалось для их корректной работы нужно устанавливать совместимость у EXE файла. Что-то связанное с пользователями в Windows, уж не помню что.
Так или иначе это - мои любимы голоса, поэтому пишу в надежде что эта проблема решаемая.
Ближе к сути:
Из того что не видно на скриншоте - после чтения курсор остановился до трёх восклицательных знаков. Ещё могут отметить что проблема с этой скобкой " { " была и в моей прошлой версии, почти ровно годичной давности, но по понятным причинам проблема была мало заметна.
Также проблема появляется только когда программа читает и выделяет по слову, а вот если выделяется сразу большой кусок текста - то в нём знаки тоже перекрашены. Честно сказать, я так и не понял по в каких случая программа читает по слову, а когда читает цельный абзац. В процессе теста один текст она сначала читала по слову, затем я его скопировал и вставил обратно и она начала брать сразу весь текст. Но вот этот тестовый вариант она устойчиво читает по словам:
Может быть эти голоса слишком морально устарели для программы, но я всё равно надеюсь на лучшее. Так или иначе у меня ещё лежит билд годовалой давности, всегда можно вернутся к нему.
Решаемая эта проблема или нет - так или иначе спасибо за вашу прекрасную программу.
Здравствуйте. Если я правильно понимаю, то .dic словари в балаболке работают только c оффлайн голосами. Поэтому для исправления ударений для онлайн голосов я проставляю ударения с помощью словарей омографов, но с одним правильным вариантом, внося его в фразы с омографом. Меня такой вариант, когда я могу полностью контролировать произношение без всяких промежуточных словарей, более, чем устраивает. Но есть одно "но". В этих словарях нельзя заменить два слова одним, чтобы правильно произносились слова с переносом ударения на предлог. Например: не было=н+ебыло за руки=з+аруки на пол=н+апол под руки=п+одруки и т.п. за нос, за уши, за угол, за волосы, на ночь, до смерти,.. Может можно как-то это реализовать, например, проставляя по запросу ударение из словарей .dic прямо в тексте, как из словарей .hmg или разрешив в словарях .hmg заменять раздельное написание предлогов на слитное, чтобы головы героев склонялись не на бок, а н+абок?
Suravel Вы можете "обработать" словарями текст в главном окне, с помощью пункта главного меню Настройки | Коррекция произношения | Показать изменённый текст. Этот модифицированный текст и используйте для работы с онлайн-сервисами.
Действительно, в окне для онлайн-сервисов словари сейчас не применяются. Это связано с тем, что текст, отправляемый на сервер, ограничен по длине; и у каждого сервера свое ограничение. Иногда текст запроса ограничен даже не количеством символов, а количеством байтов: соответственно, надо еще проверять, сколько байтов занимает текст в кодировке UTF-8 (латинская буква или цифра - это один байт, русская буква - два байта и т.д.). "Балаболка" делит текст на абзацы и предложения, стараясь уложиться в заданные лимиты запроса для каждого онлайн-сервиса (а иногда приходится делить на части очень длинные предложения). Если при этом еще применять правила из словаря, которые и могут изменить длину текста, и могут заменить, например, большую букву в начале предложения на маленькую, могут убрать точку в конце предложения, то нормально поделить такой текст программа уже не сможет.
Я решил пока облегчить себе жизнь и использовать при работе с онлайн-сервисами только лишь оригинальный текст, извлеченный из файла.
Вы можете "обработать" словарями текст в главном окне, с помощью пункта главного меню Настройки | Коррекция произношения | Показать изменённый текст. Этот модифицированный текст и используйте для работы с онлайн-сервисами.
Огромное спасибо за оперативный ответ. Я уж и не помню сколько лет пользуюсь балаболкой, ещё с 14-й версии, и всегда удивлялась насколько продумана, до мелочей, в программе работа с текстом, а вот о наличии такой функции не знала. Именно о такой возможности я и спрашивала. Говорят, что сейчас это "не модно", но я всегда провожу предварительную обработку текста в главном окне. Просто не знала, что в отдельном окне можно получить измененный текст, да ещё и сохранить его. Это всё, что нужно для комфортной работы. Ещё раз спасибо!
Спасибо! В новой версии проблема с не перекрашенными знаками пропала.
Хотя стоит отметить что есть ещё проблема в том как и когда идёт перекраска некоторых символов. Это тоже наблюдается в режиме чтения по слову, хоть в этот раз она не специфична для моих старых голосов. По крайней мере Microsoft Zira тоже показывает такое поведение.
К сожалению я не могу предоставить фрагмент для устойчивого воспроизведения проблемы т.к. вставленный фрагмент из одного текста в новой вкладке уже читается по другому. Но это легко заметить в любом тексте с английским видом написания диалогов: через кавычки а не дифисы. Я взял первый попавшийся Epub с англоязычной Алисой в Стране Чудес и в диалогах проблема проявилась.
Суть же в том что разного рода символы перекрашиваются только после начала чтения второго слова в абзаце. К сожалению, вне остального текста эта строка проблему не показывает, но для умозрительного понимания её хватит.
"Not like cats!" cried the Mouse, in a shrill, passionate voice. "Would you like cats if you were me?"
Собственно, сначала подсвечивается первое слово, кавычка в этот момент остается непрочитанной, и только при начале чтения второго слова кавычка перекрашивается.
Такое может происходить с различными символами, не только с кавычками разного рода, но по понятным причинам встретить абзац что начинается со скобок, апострофа или чего-нибудь ещё более экзотического в русскоязычном тексте не так просто.
Проблема минорная и жить особо не мешает, чуть перфекционизм царапает да и только. Но на всякий случай решил отметить.
Во! Нашел способ как показать. Вот текст. Также хочу отметить что проблема начинает проявлятся не с первых строк, а с их повторов. Устойчиво как на моих голосах, так и на SAPI 5 MS Irina
Код
"“Смешанные кавычки.
'`Апостроф+гравис.
»Закрывающая ёлочка.
‹Одинарная ёлочка.
„Нижние кавычки.
»«Странная последовательность.
«—Кавычки и тире.
(“Кавычки внутри скобок.
{‘Вложенные разные.
"Что дальше?
'Конец.""“Смешанные кавычки.
'`Апостроф+гравис.
»Закрывающая ёлочка.
‹Одинарная ёлочка.
„Нижние кавычки.
»«Странная последовательность.
«—Кавычки и тире.
(“Кавычки внутри скобок.
{‘Вложенные разные.
"Что дальше?
'Конец."
Помимо этого я заметил что программа теперь при открытии docx файлов не добавляет им пустую строку между абзацами. Не уверен когда это изменилось, в 904 версии я docx не открывал, при обноружении ошибки я вернулся на билд годовалой давности, там открыл docx и после одбновления до 905 этот открытый файл лишился пустых строк между абзацами. При возвращении на билд годовалой давности файл снова открылся с пустыми строками. Потестировав разные docx файлы это проявилось во всех них.
Так если перевести epub через pandoc в docx, то оригинальный файл будет с пустыми строками, а docx в новой версии откроется без них.
Это решается заменой ^p на ^p^p, но я не до конца уверен что так должно быть по умолчанию.
P.S.
Ещё один вопрос: можно ли в окошке перевода сделать так чтобы автоматически вставлялся выделенный текст? Или хотя бы была кнопка импорта выделенного фрагмента? А то там только вставка из буфера обмена да всего документа сразу.
Я надеюсь когда-нибудь и англоязычные книги в Балаболке слушать, но моё знание ещё недостаточно чтобы не спотыкаться о некоторые слова и хотелось бы удобно уточнять свои пробелы. Сейчас же это требует самому копи-пастить что не столь удобно.
Kei В новой версии исправлена ошибка с окрашиванием символов, расположенных слева от текущего слова (при чтении голосами SAPI 5). Проверил Ваши примеры текста: при чтении голосами Microsoft Irina и Microsoft Zira символы окрашиваются правильно.
Извлечение текста из файлов форматов DOCX и ODT было обновлено: вместо вставки пустой строки между абзацами программа вставляет "красную строку" в начало абзаца (если в документе есть такой отступ). Но да, Вы правы: получилось не очень хорошо; лучше вернуть так, как было раньше. Обещаю подумать над этим.
Кнопку для вставки выделенного текста можно добавить. Подумаю над этим тоже. Спасибо за идею.





 (5,1 Mb)
(5,1 Mb)