|
Скрипты для Demagog
|
|
| flegont | Дата: Среда, 21.07.2021, 17:05 | Сообщение #1 |
 V.I.P.
Группа: Модераторы
Сообщений: 141
Статус: Offline
| Начало темы здесь (ссылка на архивную копию форума mytts.info)
 (6.6 Mb) архивная копия начала текущей ветки с форума mytts.info - для офлайн просмотра и поиска по всем страницам (6.6 Mb) архивная копия начала текущей ветки с форума mytts.info - для офлайн просмотра и поиска по всем страницам
|
| |
| |
| flegont | Дата: Пятница, 01.12.2023, 19:34 | Сообщение #61 |
|
V.I.P.
Группа: Модераторы
Сообщений: 141
Статус: Offline
| В питоне, оказывается, есть средство обойтись без экранирования слэшей и прочих спецсимволов.
Как в Lua двойные квадратные скобки: [[строка\со\слэшами]]
Так в питоне специальная приставка из одной буквы r: r'строка\со\слэшами'
Кавычки могут быть одинарными или двойными - дело вкуса.
Я выложил релиз вер. 422 x64 с доступными питону функциями RexRepl(), DicRepl()
Запускал на ней чисто питоновский скрипт без обращенияк Lua.
Сравнение результатов:
# Python>hash-test 3.txt
# Lua>
34af71ca0dfe76c0a3840d9cee41a8d2*Нахалка.txt
3dea20f63d9d0e7de69c04b5040108ff*Нахалка (edit for piper).txt
# Python>hash-test 4a.txt
34af71ca0dfe76c0a3840d9cee41a8d2*Нахалка.txt
3dea20f63d9d0e7de69c04b5040108ff*Нахалка (edit for piper).txt
|
| |
| |
| tonio_k | Дата: Суббота, 02.12.2023, 00:28 | Сообщение #62 |

Группа: Пользователи
Сообщений: 179
Статус: Offline
| Цитата flegont (  ) Я выложил релиз вер. 422 x64
или релиз не обновился или файлик с ошибкой?
|
| |
| |
| flegont | Дата: Суббота, 02.12.2023, 08:27 | Сообщение #63 |
|
V.I.P.
Группа: Модераторы
Сообщений: 141
Статус: Offline
| Вы скачали Demagog.zip, извлекли из него новый экзешник Demagog.exe и заменили в уже имеющемся комплекте?
Надо еще заменить файл ..\Demagog\profiles\mygui.py
В нем, как раз, и добавлено описание новых функций RexRepl и DicRepl, т.к. в самОм Демагоге добавлена для питона лишь одна универсальная функция PowerRepl, которая может делать многие вещи в зависимости от параметра mode = 1, 2, и т.д. (Пока задействованы 1 и 2 - действовать регулярками, или действовать по правилам dic).
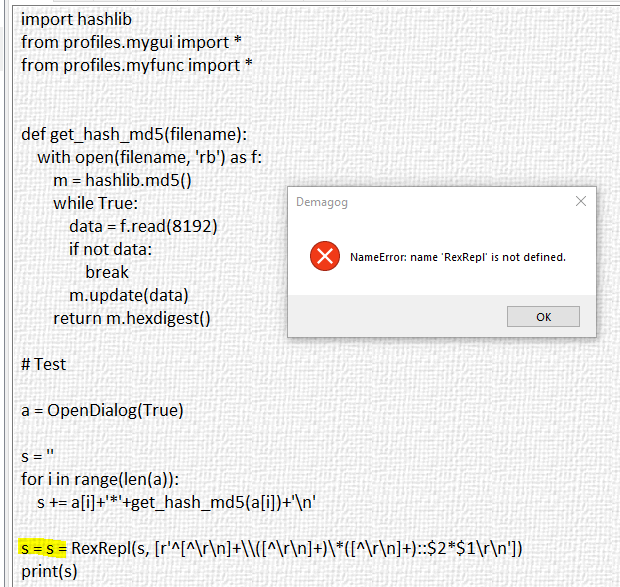
P.S. В примере hash-test 4a.txt опять последствия моих быстрых, но неуклюжих копи-пасте:
s = s = RexRepl(s, ...
Должно быть просто
s = RexRepl(s, ...
Но... ошибки нет! Питон такой хитрый язык, что видя, например: x = x = x = 2*2 честно делает все присваивания справа налево, и получает в итоге x = 4
Зачем это нужно: А вот:
z = y = x = 2*2
print(x,y,z)
Ответ: 4 4 4
Множественное присваивание 
|
| |
| |
| tonio_k | Дата: Суббота, 02.12.2023, 13:27 | Сообщение #64 |
|
Группа: Пользователи
Сообщений: 179
Статус: Offline
| Цитата flegont ( ) извлекли из него новый экзешник Demagog.exe и заменили в уже имеющемся комплекте? |
| |
| |
| flegont | Дата: Суббота, 02.12.2023, 13:56 | Сообщение #65 |
|
V.I.P.
Группа: Модераторы
Сообщений: 141
Статус: Offline
| Насчет хеш-сумм... даже не знаю. 99.999% пользователей понятия не имеют, что это такое, и эта информация для них бесполезна.
Но поэкспериментировать можно.
|
| |
| |
| flegont | Дата: Среда, 06.12.2023, 09:18 | Сообщение #66 |
|
V.I.P.
Группа: Модераторы
Сообщений: 141
Статус: Offline
| Silero + CUDA ?
Недавно передо мной возник (точнее, его передо мной поставили  ) вопрос: известно ли мне, что некоторым энтузиастам удалось выполнить синтез речи голосами Силеро, с использованием видеокарты? ) вопрос: известно ли мне, что некоторым энтузиастам удалось выполнить синтез речи голосами Силеро, с использованием видеокарты?
Известно мне это не было, энтузиазма я не испытывал, а лишь с недовольством вспоминал, что pytorch в варианте для CUDA имеет размер 4+ гигабайта.
Но, что-то надо было отвечать, и я зашел на питорч.орг глянуть, что там нового. Да, версия 2.1.1. Хошь для cpu, хошь для cuda. Уныло нажал "скачать" для этой самой куды, и с трепетом увидел размер закачки: 5.4 гигабайта.
Впихнул этот огромного размера торч в специально приготовленный вариант сборки, поменял в скрипте torch.device('cpu') на torch.device('cuda') и запустил скрипт на выполнение...
При первом запуске, модель Силеро всегда "раскочегаривается" после некоторой паузы, в этот раз пауза была заметно дольше. "Зависла, хрень такая...", - мрачно подумал я.
Как вдруг в строке состояния воникли и замелькали цифры, показывающие процент выполнения.
Повесть Киплинга "Отважные мореплаватели" сконвертировалась на Силеро V3.1 в аудио за 3 мин 50 сек вместо прежних 25 минут.
Вывод: Да, на компьютерах с видеокартой от фирмы Nvidia, синтез-речи Силеро работает в 5-6 раз быстрее в режиме CUDA, чем на на CPU. Это для видеокарты Geforse 3070 для ноутбуков. Для более мощной будет еще быстрее.
Эффект ускорения наблюдается для достаточно больших текстов. Потому что на всяких там рассказиках и байках-анекдотах, видеокарта попросту не успевает "войти в режим", если можно так выразиться.
А теперь вопрос: А нужна ли сборка, которая даже в виде архива занимает более 2 гб? Тем более, что выяснить, будет ли она работать на данном конкретном ПК, можно лишь только после попытки ее запустить? Не у всех есть видеокарты именно Nvidia, и не все видеокарты Nvidia поддерживают CUDA...
|
| |
| |
| flegont | Дата: Среда, 06.12.2023, 12:39 | Сообщение #67 |
|
V.I.P.
Группа: Модераторы
Сообщений: 141
Статус: Offline
| # Свойства текста "Kipling_Otvazhnye-moreplavateli.txt"
129,21 машинописных страниц = 6,01 авторских листов
Знаков (без пробелов): 196197
Знаков (с пробелами): 240325
Слов в тексте: 39065
Средняя длина слова: 5,02
Абзацев: 1266
Средняя длина абзаца: 189,83
Максимальная длина абзаца: 1534
Строк: 2984
Латиница: 0,03% (13 слов)
Конвертация в аудио Silero V3.1 + CUDA: 3 мин 49 сек
# Свойства текста "Efremov_Tais-Afinskaya.MFWeIg.281283.fb2"
555,41 машинописных страниц = 25,83 авторских листов
Знаков (без пробелов): 865196
Знаков (с пробелами): 1033069
Слов в тексте: 151367
Средняя длина слова: 5,72
Абзацев: 4001
Средняя длина абзаца: 258,20
Максимальная длина абзаца: 15726
Строк: 12690
Латиница: 0,02% (30 слов)
Конвертация в аудио Silero V3.1 + CUDA: 16 мин 18 сек
|
| |
| |
| flegont | Дата: Среда, 06.12.2023, 16:55 | Сообщение #68 |
|
V.I.P.
Группа: Модераторы
Сообщений: 141
Статус: Offline
| Хм... попутно выяснилось, что если взять вариант pytorch 2.1.1 для CPU, то прежняя сборка - Demagog-x64-Silero, с этим новым торчем тоже работает несколько быстрее: в 1.3 .. 1.5 раза. За счет лучшей работы нового торча под cpu (?!)
|
| |
| |
| wasyaka | Дата: Среда, 06.12.2023, 20:48 | Сообщение #69 |
|
Группа: Модераторы
Сообщений: 35
Статус: Offline
| Цитата tonio_k ( ) 20_ПАКЕТНАЯ ОБРАБОТКА - ОБРАБОТКА И ЗАПИСЬ ВСЕХ КНИГ TXT В ПАПКЕ
Вопрос: возможно ли скриптом обработать один текст темя группами словарей? (три раза подряд) проблема в быстром индекс и структуре словарей (под категорию _index попадают 4.... а если #[%w,]*%f[%w]стены%f[%W][%w,]*[^#]+ в первом срабатывают а остальные - лесом(игнор). в итоге не сложно клавой пощёлкать, но ...
Сообщение отредактировал wasyaka - Среда, 06.12.2023, 20:51 |
| |
| |
| tonio_k | Дата: Среда, 06.12.2023, 20:59 | Сообщение #70 |
|
Группа: Пользователи
Сообщений: 179
Статус: Offline
| По идее, можно сделать несколько словарей, даже копии друг друга что бы содержали (index), тогда 4 одинаковых словаря должны отработать 4 раза к тексту подряд
|
| |
| |
| tonio_k | Дата: Среда, 06.12.2023, 21:07 | Сообщение #71 |
|
Группа: Пользователи
Сообщений: 179
Статус: Offline
| А ещё, вы можете нажать комбинацию
Ctrl+Shift+8 к выделеному тексту. И будет видно какие словари срабатывают, какие правила применяютсяи и можно понять где проблема
UPD
Если при этом, в статистке какой-то словарь пропущен, то это может означать, что словарь отработал, но изменения в тесте не произошли, поэтому в статистику он не попал.
Сообщение отредактировал tonio_k - Среда, 06.12.2023, 21:11 |
| |
| |
| wasyaka | Дата: Четверг, 07.12.2023, 19:35 | Сообщение #72 |
|
Группа: Модераторы
Сообщений: 35
Статус: Offline
| Цитата tonio_k ( ) По идее, можно сделать несколько словарей, даже копии друг друга что бы содержали (index), тогда 4 одинаковых словаря должны отработать 4 раза к тексту подряд
сейчас время свободное появилось - по экспериментирую.
|
| |
| |
| tonio_k | Дата: Четверг, 07.12.2023, 20:30 | Сообщение #73 |
|
Группа: Пользователи
Сообщений: 179
Статус: Offline
| Цитата wasyaka ( ) он принимает все словари с _index как один
Сообщение отредактировал tonio_k - Четверг, 07.12.2023, 23:11 |
| |
| |
| wasyaka | Дата: Суббота, 09.12.2023, 16:43 | Сообщение #74 |
|
Группа: Модераторы
Сообщений: 35
Статус: Offline
| Цитата tonio_k ( ) Поэтому, важно прописывать все возможные словоформы в разделе ключевых слов в словаре с правилами под ним (в словаре с index в названии).
но в первом
\bвсеъ\b=всЕ\bвсёъ\b=всЁ
не мешало срабатывать.... 
|
| |
| |
| tonio_k | Дата: Суббота, 09.12.2023, 17:18 | Сообщение #75 |
|
Группа: Пользователи
Сообщений: 179
Статус: Offline
| Могу предположить, что lua цепляет правила в ansi кодировке, а ваше правило содержит символ в utf8 кодировке. И когда генерируется временный "мини словарь" да текущего отрезка, этот символ "пропадает" и правило не срабатывает.
Было бы здорово, если вы мне пришлёте словарики и кусок текста в личку. Будет время, я внимательно посмотрю что там такое?
|
| |
| |